PythonでWebスクレイピングしてみた
私はジャズが好きで、ちょくちょくライブに行きます。
前々から複数のライブハウスの予定を一気に表示してくれるサービスなんて無いかなあと思っておりました。
ふと調べてみたら、あるじゃないですか簡単そうな方法が・・・!
ということでPythonでWebスクレイピングに挑戦してみました。
最も有名と言われているスクレイピングのPythonライブラリ、PyQueryを使います。
例のごとく、インストールはpipで一発です。
pip install pyquery
PyQueryではその名の通りjQuery風のセレクタを使えるということだったのですが、jQueryなにそれ美味しいの?状態だったので、ドットインストールでひと通り勉強。
凄くシンプルな記述で、対象のhtmlから扱いたい要素を指定できるということですね。
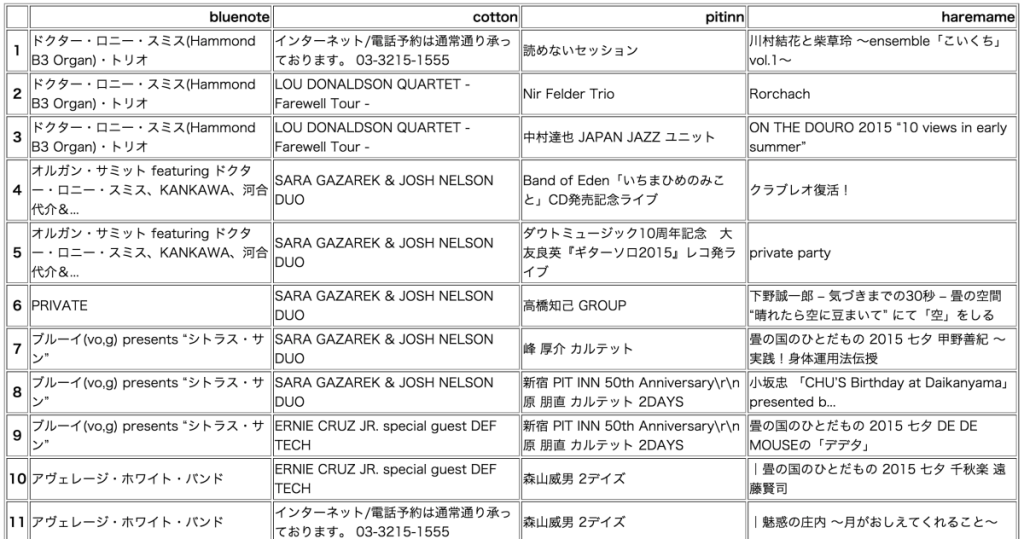
今回は、ブルーノート、コットンクラブ、ピットイン、晴れたら空に豆まいての4つのライブハウスから、指定した月の日にちごとにライブの予定(ライブのタイトル)を取得し、データフレームにおさめて、最後にhtmlの表にして吐き出すスクリプトを書いてみました。
なにしろ独学素人なので美しくないところもあるかと思いますが、とりあえず欲しい結果は得られた模様です。
それぞれのサイトのhtmlをじっくり見ながら、どうやって欲しい情報(ライブのタイトル)が記述されてる要素を指定するか検討します。
# -*- coding:utf-8 -*-
from urllib import request
from pyquery import PyQuery as pq
import pandas as pd
from pandas import Series, DataFrame
# 取得したい年と月
year = 2015
month = 7
# 1ケタの月が01でなく1になってしまうので調整
if month < 10:
monthstr = '0' + str(month)
else:
monthstr = str(month)
# 指定した月の日にちのリストを作成
import calendar
days = [day for day in range(1, calendar.monthrange(year, month)[1] + 1)]
# -----------------------------------------------------------------------------
# ブルーノートから取得
resp = request.urlopen("https://reserve.bluenote.co.jp/reserve/schedule/move/%d%s" % (year, monthstr))
html = resp.read().decode("utf-8")
query = pq(html)
bluenoteResults = []
for bluenote_days in query.find("span.day").closest(".oldBox"):
if pq(bluenote_days)('tr')('td:last').text() == str('PRIVATE'):
bluenoteResults.append('PRIVATE')
else:
bluenoteResults.append(pq(bluenote_days).next().next().find("span.text:eq(0)").text())
for bluenote_days in query.find("span.day").closest(".todayBox"):
if pq(bluenote_days)('tr')('td:last').text() == str('PRIVATE'):
bluenoteResults.append('PRIVATE')
else:
bluenoteResults.append(pq(bluenote_days).next().next().next().find("span.text:eq(0)").text())
for bluenote_days in query.find("span.day").closest(".later"):
if pq(bluenote_days)('tr')('td:last').text() == str('PRIVATE'):
bluenoteResults.append('PRIVATE')
else:
bluenoteResults.append(pq(bluenote_days).next().next().find("span.text:eq(0)").text())
bluenoteResults = DataFrame(bluenoteResults, index=[days], columns=["bluenote"])
# -----------------------------------------------------------------------------
# コットンクラブから取得
resp = request.urlopen("http://www.cottonclubjapan.co.jp/jp/schedule/%d%s.php" % (year, monthstr))
html = resp.read().decode("utf-8")
query = pq(html)
cottonResults = DataFrame(days, index=[days], columns=["cotton"])
for i in days:
for cotton_lives in query.find("#sched_box"):
if '%d.%d.' % (month, i) in pq(cotton_lives).find('p.day').text():
cottonResults.ix[i] = pq(cotton_lives).find('p.title').text()
else:
pass
# -----------------------------------------------------------------------------
# ピットインから取得
if month == 1:
pitinnMonthStr = '12'
pitinnYear = year - 1
elif month < 10:
pitinnMonthStr = '0' + str(month - 1)
pitinnYear = year
else:
pitinnMonthStr = str(month - 1)
pitinnYear = year
resp = request.urlopen("http://www.m-works.info/pitinn/calend_j_p.php?YM=%d%s&MOVE=Next" % (pitinnYear, pitinnMonthStr))
html = resp.read().decode("utf-8")
query = pq(html)
pitinnResults = []
for pitinn_days in query.find("B"):
pitinnResults.append(pq(pitinn_days).text())
pitinnResults = DataFrame(pitinnResults[1:], index=[days], columns=["pitinn"])
# -----------------------------------------------------------------------------
# 晴れ豆から取得
resp = request.urlopen("http://mameromantic.com/?m=%d%s&cat=1" % (year, monthstr))
html = resp.read().decode("utf-8")
query = pq(html)
hareResults = DataFrame(days, index=[days], columns=["haremame"])
for i in days:
for hare_lives in query.find("div.entry"):
if '%d.%d.' % (month, i) in pq(hare_lives).find('a:eq(0)').text():
hareResults.ix[i] = pq(hare_lives).find('a:eq(0)').text()[12:-2]
else:
pass
allResults = pd.concat([bluenoteResults, cottonResults, pitinnResults, hareResults], axis=1)
htmlout = allResults.to_html()
f = open('jazzlive%d%s.html' % (year, monthstr), 'w')
f.write(htmlout)
f.close()
こんな感じで、以下のような表が得られました。
This Post Has 0 Comments